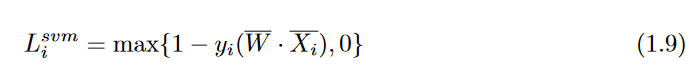Relationship with Support Vector Machines
The perceptron criterion is a shifted version of the hinge loss used in support vector machines .
The hinge loss looks even more similar to the zero-one loss criterion of Equation 1.7, and is defined as follows
Note that the perceptron does not keep the constant term of 1 on the right-hand side of Equation 1.7, whereas the hinge loss keeps this constant within the maximization function.This change does not affect the algebraic expression for the gradient, but it does change
which points are loss less and should not cause an update. The relationship between the perceptron criterion and the hinge loss is shown in Figure1.6.
This similarity becomes particularly evident when the perceptron
updates of Equation 1.6 are rewritten as follows:
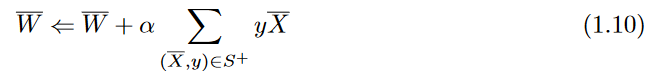
Here,S
+ is defined as the set of all misclassified training points X̄ ∈ S that satisfy the condition y(W̄.X̄) < 0.
This update seems to look somewhat different from the perceptron,because the perceptron uses the error E(X̄) for the update,
which is replaced withyin theupdate above. A key point is that the (integer) error value E(X̄)=(y-sign{W̄.X̄}) ∈ {-2,+2} can never be 0
for misclassified points in S
+. Therefore, we have E(X̄) = 2y for misclassified points,and E(X̄) can be replaced with y in the updates after absorbing the factor of 2 within the learning rate.
This update is identical to that used by the primal support vector machine (SVM) algorithm ,
except that the updates are performed onlyfor the misclassified points in the perceptron,
whereas the SVM also uses the marginally correct points near the decision boundary for updates.
Note that the SVM uses the condition y(W̄.X̄) < 1 [instead of using the condition y(W̄.X̄) < 0] to define S
+,which is one of the key differences
between the two algorithms. This point shows that the perceptron is fundamentally
not very different from well-known machine learning algorithms like thesupport vector machine in spite of its different origins.
Freund and Schapire provide abeautiful exposition of the role of margin in improving stability of the perceptron and also its relationship
with the support vector machine. It turns out that many traditional machine learning models can be viewed as minor
variations of shallow neural architectures like the perceptron. The relationships between classical machine learning models and shallow neural networks
are described in detail in later posts.